

The four DORA metrics — Deployment Frequency, Change Failure Rate, Mean Lead Time for Changes, and Mean Time to Recovery — were identified by the DevOps Research & Assessment group as the four metrics most strongly statistically correlated with success as a company.
Within those four metrics, the institute defined ranges that are correlated with meaningfully different company outcomes. They describe companies based on the outcomes they achieve as “High Performing,” “Medium Performing,” or “Low Performing.”
Moving between categories — for example, improving your Deployment Frequency from “between once per month and once every six months” to “between once per month and once every week” — leads to a statistically significant change in the success of a business. Moving within a bucket (for example, from once per month to twice per month) may be an improvement, but was not shown to drive the same level of shift in outcome.
DORA calculations are used as reference points across the industry, yet, there is no agreed-upon approach for DORA assessment, or accurately measuring DORA metrics. To set the original performance benchmarks, the DORA group surveyed more than 31,000 engineering professionals across the world over a span of six years, but responses were not based on standardized, precise data.
DORA metrics have been interpreted and calculated differently for different organizations, and even for teams within the same organization. This limits leaders’ ability to draw accurate conclusions about speed and stability across teams, organizations, and industries.
Because of this, there are subtle pitfalls to using automated DORA metrics as performance indicators.
Code Climate Velocity measures DORA metrics with real data, as opposed to proxy data, for the most useful understanding of your team health and CI/CD processes.
Code Climate’s Approach to DORA Assessment
As mentioned, there are many different approaches to automating the measurement of the DORA metrics in the market. In order to enable engineering executives to understand how their organization is performing across the four DORA metrics, we wanted to provide the most accurate and actionable measurement of outcomes in Velocity.
Our approach relies on analytical rigor rather than gut feel, so engineering leaders can understand where to investigate issues within their software practices, and demonstrate to executives the impact of engineering on business outcomes.
Using Real Incident Data, Not Proxy Data for DORA Calculations
Not every platform tracks Incident data the same way; many platforms use proxy data, resulting in lower-quality insights. Velocity instead uses actual Incident data, leading to more accurate assessment of your DevOps processes.
Velocity can ingest your team’s Incident data directly from Jira and Velocity’s Incident API. These integrations provide a way for every team to track metrics in the way that most accurately reflects how they work.
The Most Actionable Data
We made it possible for engineering leaders to surface DORA metrics in Velocity’s Analytics module, so that customers can see their DORA metrics alongside other Velocity metrics, and gain a more holistic overview of their SDLC practices.
Teams can evaluate their performance against industry benchmarks, as well as between other teams within the organization, to see which performance bucket they fall under: high, medium, or low. Based on that information, they can scale effective processes across the organization, or change processes and measure their impact.
Balancing Speed with Stability: How Velocity Metrics Contextualize DORA Metrics
If teams evaluated DORA metrics in isolation and discovered that their teams have a high Deployment Frequency or that they deploy multiple times a day, they may still be considered “high performing” — yet we know this does not tell the whole story of their software delivery. Velocity metrics and other DORA metrics within the Analytics module help contextualize the data, so that teams can understand how to balance speed with stability.
For example, the Velocity Metric PR size (number of lines of code added, changed, or removed) can be a useful counterpoint to Deployment Frequency. If you view these metrics together in Velocity’s Analytics module, you can see a correlation between the two — does a low Deployment Frequency often correlate with a larger PR size? If so, leaders now have data-backed reasoning to encourage developers to submit smaller units of work.
This doesn’t necessarily mean that your Deployment Frequency will be improved with smaller PR sizes, but it does provide a starting point to try and improve that metric. Leaders can note when this change was implemented and observe its impact over time. If Deployment Frequency is improved, leaders can scale these best practices across the organization. If not, it’s time to dig deeper.
Here are a few examples of Velocity metrics you can pair with DORA metrics for actionable insights:
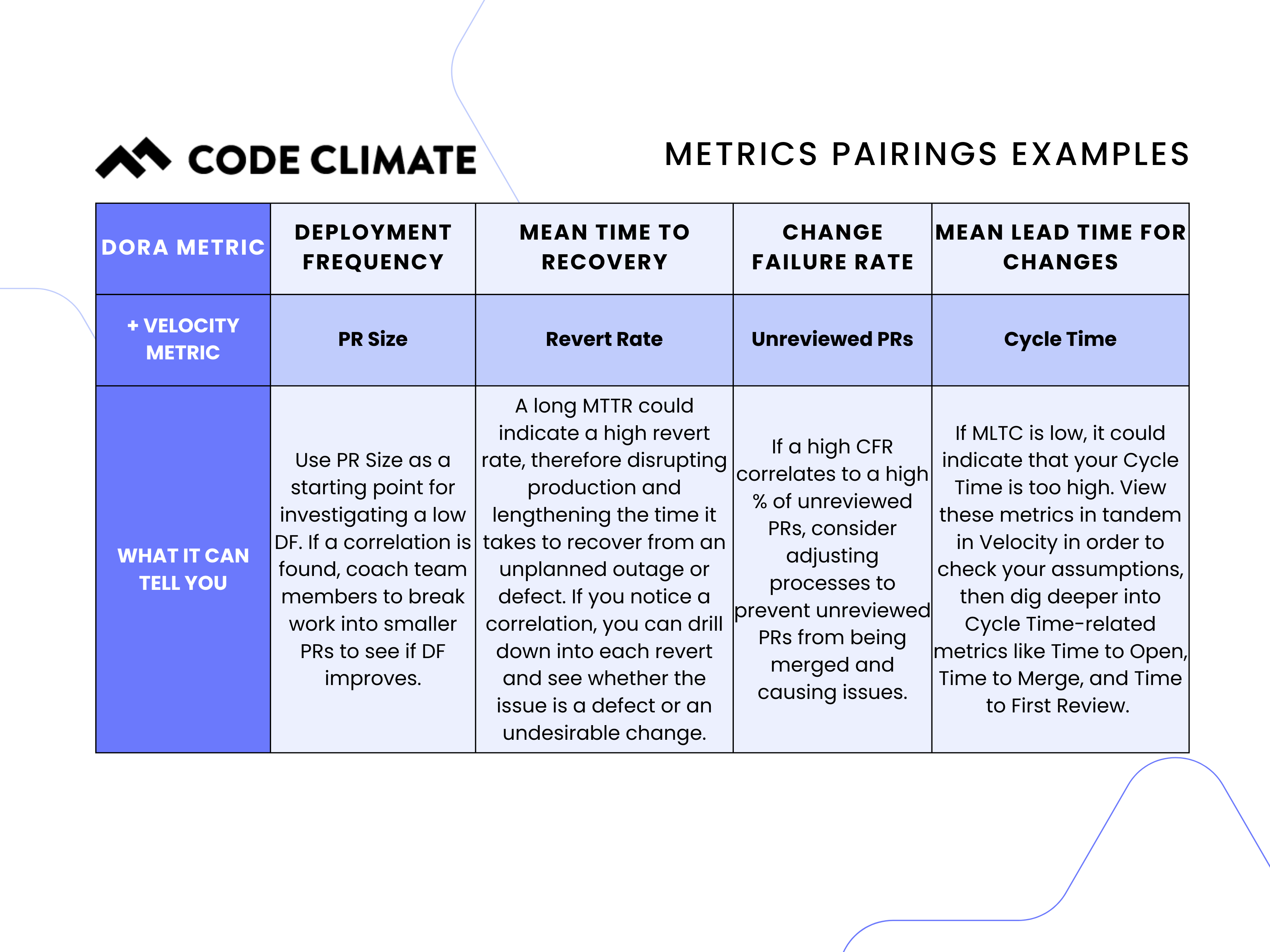
DORA Metrics Definitions
Deployment Frequency – A measurement of how frequently the engineering team is deploying code to production.
Deployment Frequency helps engineering leadership benchmark how often the team is shipping software to customers, and therefore how quickly they are able to get work out and learn from those customers. The best teams deploy multiple times per day, meaning they deploy on-demand, as code is ready to be shipped. The higher your Deployment Frequency, the more often code is going out to end users. Overall, the goal is to ship small and often as possible.
Mean Lead Time for Changes – A measurement of how long, on average, it takes to go from code committed to code successfully running in production.
Mean Lead Time for Changes helps engineering leadership understand the efficiency of their development process once coding has begun and serves as a way to understand how quickly work, once prioritized, is delivered to customers. The best teams are able to go from code committed to code running in production in less than one day, on average.
Change Failure Rate – The percentage of deployments causing a failure in production. If one or more incidents occur after deployment, that is considered a “failed” deployment.
Change Failure Rate helps engineering leaders understand the stability of the code that is being developed and shipped to customers, and can improve developers’ confidence in deployment. Every failure in production takes away time from developing new features and ultimately has negative impacts on customers.
It’s important, however, that leaders view Change Failure Rate alongside Deployment Frequency and Mean Lead Time for Changes. The less frequently you deploy, the lower (and better) your Change Failure Rate will likely be. Thus, viewing these metrics in conjunction with one another allows you to assess holistically both throughput and stability. Both are important, and high-performing organizations are able to strike a balance of delivering high quality code quickly and frequently.
Mean Time to Recovery – A measurement of how long, on average, it takes to recover from a failure in production.
Even with extensive code review and testing, failures are inevitable. Mean Time to Recovery helps engineering leaders understand how quickly the team is able to recover from failures in production when they do happen. Ensuring that your team has the right processes in place to detect, diagnose, and resolve issues is critical to minimizing downtime for customers.
Additionally, longer recovery times detract from time spent on features, and account for a longer period of time during which your customers are either unable to interact with your product, or are having a sub-optimal experience.
Doing DORA Better
Though there is no industry standard for calculating and optimizing your DORA metrics, Velocity’s use of customers’ actual Incident data, and ability to contextualize that data in our Analytics module, can help teams better understand the strengths and weaknesses of their DevOps process and work towards excelling as an engineering organization.
Interested in learning which performance benchmark your team falls under, and how you can scale or alter your engineering processes? Reach out to a Velocity specialist.
Get articles like this in your inbox.
Trending from Code Climate
1.
Engineering Leaders Share Thoughts on Leadership in Disrupted Times in a New Survey
For engineering teams, disruption to the business can have a significant impact on the ability to deliver and meet goals. These disruptions are often a result of reprioritization and budget changes on an organizational level, and are amplified during times of transition or economic instability.

2.
Built In’s 2023 Best Places to Work — Why Code Climate Made the List
At Code Climate, we value collaboration and growth, and strive for greatness within our product and workplace. For us, this means fostering a supportive, challenging, people-first culture. Thanks to an emphasis on these values, we’ve earned spots on three of Built In’s 2023 Best Places to Work awards lists, including New York City Best Startups to Work For, New York City Best Places to Work, and U.S. Best Startups to Work For.

3.
Turnkey Deployment Delivers Day-One Value for Yottaa
Learn how Yottaa gained immediate value from Code Climate Velocity right out of the box.

Get articles like this in your inbox.
Get more articles just like these delivered straight to your inbox
Stay up to date on the latest insights for data-driven engineering leaders.